출처: http://msdn.microsoft.com/ko-kr/magazine/cc163681(en-us).aspx
젠장, 이건 한국어 선택해도 한국어로 안나오는 페이지네... 결국 해석해야 할듯...
C++/CLI is a self-contained, component-based dynamic programming language that, like C# or Java, is derived from C++. Unlike those languages, however, we have worked hard to integrate C++/CLI into ISO-C++, using the historical model of evolving the C/C++ programming language to support modern programming paradigms. You can say that C++/CLI is to C++ as C++ is to C. More generally, you can view the evolution leading to C++/CLI in the following historical context:
C++/CLI는 'Self-contained (스스로 모두 내포하고 있는 - 즉, 완전체)'하고 컴포넌트에 기반한 동적 프로그래밍 언어다. 마치 C# 또는 자바처럼 C++에 근간을 두고 있는 언어들 처럼 말이다. 하지만 그런 언어들 (C#이나 Java)과는 달리 우리 (Microsoft사)는 C++/CLI를 ISO-C++ (표준 C++을 말함) 형태로 만들기 위해서 무척이나 노력했단다... 뭐 쉽지 않았을 것 같다. C++ 에서 C++/CLI로 가는 것은 C에서 C++로 가는 것 만큼이나 큰 변화였다는 이야기. 다음 문서들을 보게 되면 얼마나 큰 변화가 있는지 알거다... 허허.. 그걸 언제 다 읽어봐.... 제일 마지막꺼만 읽어보면 괜춘할듯.
- BCPL (Basic Computer Programming Language)
- B (Ken Thompson, original UNIX work)
- C (Dennis Ritchie, adding type and control structure to B)
- C with Classes (~1979)
- C84 (~1984)
- Cfront, release E (~1984-to universities)
- Cfront, release 1.0 (1985-to the world )—20th birthday
- Multiple/Virtual Inheritance (MI) programming (~1988)
- Generic Programming (~1991) (templates)
- ANSI C++/ ISO-C++ (~1996)
- Dynamic Component programming (~2005) (C++/CLI)
What is C++/CLI?
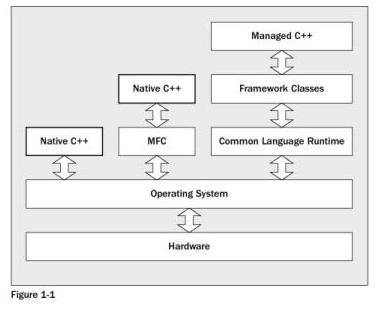
C++/CLI represents a tuple. C++ refers, of course, to the C++ programming language invented by Bjarne Stroustrup at Bell Laboratories. It supports a static object model that is optimized for the speed and size of its executables. However, it doesn't support run-time modification of the program other than heap allocation. It allows unlimited access to the underlying machine, but very little access to the types active in the running program and no real access to the associated infrastructure of that program. Herb Sutter, a former colleague of mine at Microsoft and the chief architect of C++/CLI, refers to C++ as a concrete language.
CLI refers to the Common Language Infrastructure, a multitiered architecture supporting a dynamic component programming model. In many ways, this represents a complete reversal of the C++ object model. A runtime software layer, the virtual execution system, runs between the program and the underlying operating system. Access to the underlying machine is fairly constrained. Access to the types active in the executing program and the associated program infrastructure—both as discovery and construction—is supported. The slash (/) represents a binding between C++ and the CLI. The details surrounding this binding make up the general topic of this column.
So, a first approximation of an answer to what is C++/CLI is that it is a binding of the static C++ object model to the dynamic component object model of the CLI. In short, it is how you do .NET programming using C++ rather than C# or Visual Basic®. Like C# and the CLI itself, C++/CLI is undergoing standardization under the European Computer Manufacturers Association (ECMA) and eventually under ISO.
The common language runtime (CLR) is the Microsoft version of the CLI that is specific to the Windows® operating system. Similarly, Visual C++® 2005 is the implementation of C++/CLI.
As a second approximation of an answer, I would say that C++/CLI integrates the .NET programming model within C++ in the same way as, back at Bell Laboratories, we integrated generic programming using templates within the then existing C++. In both of these cases your investment in an existing C++ codebase and in your existing C++ expertise are preserved. This was an essential baseline requirement of the design of C++/CLI.
자, 이제부터 시작이다. 머리 싸매고 읽어보자. C++/CLI는 튜플이다. 여기서 튜플이라 함은 내 생각에 서로 다른 타입이 하나의 오브젝트로 뭉쳐져 있다는 의미로 해석된다. 즉, C++과 CLI 라는 서로 다른 두 타입을 하나로 합쳐놓은 짬뽕이라는 것. C++/CLI이라는 단어에서 C++ 부분은 당연히 유명하신 Bjarne Stroustrup께서 Bell 연구소에서 만드신 것을 지칭하는 것이다. 이거 모르면 당신은 간첩? 이 C++은 기본적으로 실행파일의 속도와 크기를 위해 최적화 되어 있는 'Static Object Model'을 지원한다. Static 이라는 단어가 좀 뜬금없이 들릴수 있다. 사실 내 생각에 이 Static이라는 단어는 상대적인 의미라고 본다. 과거에 없었던 현재 시점에 어떤 기술에 비해 Static (정적)하다는 것이지 C++이 나왔을 당시에는 대박 혁명적 언어였다...
아무튼, 조금 있다 설명할 CLI를 이해하면 왜 C++이 기분나쁘게 '정적'이라고 불리는지 알게 될 것이다. 자, C++의 문제점은 Heal Allocation (힙 메모리 할당)을 제외하고는 Run-time에 변경을 허락하지 않는다. 자, Run-Time이라 함은 프로그램이 실행된 직후부터 멈추는 순간까지를 말한다. 고로 C++은 컴퓨터 자체 하부 구조에는 이른바 'Unlimited Access' 즉 무한 접근을 허락하지만 실행중인 프로그램에는 아주 미미하고 제한적인 접근만을 허락하며 프로그램이 작동하기 위해 사용하는 Infrastructure (예를 들자면 Windows 같은거)에는 실질적인 접근을 제공하지 않는다. Herb Sutter 이라는 내 친구가 있는데 이 친구가 C++/CLI를 설계를 책임진 사람이란다. 아무튼 이 친구가 말하기를 "C++은 Concrete Language다" 라고 말했단다. 직역하자면 C++은 딴딴한 언어다....... 응?? 즉, 정적이다. 별로 유동적이 않다는 것.
이제 우리의 친구 CLI를 살펴보자. CLI는 Common Language Infrastructure의 줄임말이다. 공용 언어 기반이란 뜻이네? 풀어서 설명하자면 동적 요소 프로그래밍(Dynamic Component Programming) 을 지원하는 멀티스레드를 하는 아키텍쳐란다. 이걸 단박에 이해한다면 당신은 이미 능력자. 이런 정의 자체가 이미 C++과 정반대된다. Runtime Software Layer 다른 말로는 가상 실행 시스템 (Virtual Execution System)은 프로그램과 프로그램을 실행하는 운영체제 가운데 낑겨 있는 녀석이다. 고로 컴퓨터 자체로 접근하는 것은 제한이 된다. (C++과 많이 다르다) CLI에서는 실행중인 프로그램의 타입으로 액티브하게 접근하는 것과 연관된 프로그램 infrastructure에 접근하는 것 모두 지원된다. C++/CLI 사이에 들어가는 /가 의미하는 것은 C++과 CLI의 결합을 의미한단다. 이것에 대해서 이 글에서 이야기 할꺼래.
자, 이제 C++/CLI가 뭐요? 라는 질문의 첫번째 대답을 하겠다. C++/CLI는 정적인 C++ Object Model을 동적인 Component Object Model 인 CLI와 결합한 것이다. 정적 객체 모델 C++ 더하기 동적 요소 객체 모델 CLI. 줄여서 말하자면, C#이나 Visual Basic 대신 C++ 이라는 언어를 사용해서 .NET programming을 하는 것을 말한다. 오오오... 정답! 마음에 드는 말이고 모든 것을 분명하게 선을 긋는 아주 정확한 정의다.
CLR (Common Language Runtime)은 Windows라는 운영체제를 위한 Microsoft사의 CLI라고 보면 된다. 이거 어렵게 들릴지 모르겠지만 내가 예전에 써놓은 .Net Framework에 대한 글을 보면 이해가 쉽게 될것이다.
두번째 근접한 대답으로는 C++/CLI는 과거에 벨 연구소해서 C에서 C++로 진화할때 제네릭 프로그래밍을 C에 추가한 것 처럼 C++이라는 언어에 .NET 프로그래밍 모델을 추가한 것이다. 이로써 내가 열씸히 작성해 놓은 C++ 코드들이 다 무용지물이 되지 않게 되고 C++/CLI로 흘러감으로써 엄청난 이득을 취할 수 있겠다. 그럴까??? 정말로?? ㅋㅋ
Learning C++/CLI
There are three aspects in the design of a CLI language that hold true across all languages: a mapping of language-level syntax to the underlying Common Type System (CTS), the choice of a level of detail to expose the underlying CLI infrastructure to the manipulation of the programmer, and the choice of additional functionality to provide, beyond that supported directly by the CLI.
The first item is largely the same across all CLI languages. The second and third items are where one CLI language distinguishes itself from another. Depending on the kinds of problems you need to solve, you'll choose one or another language, or possibly combine multiple CLI languages. Learning C++/CLI involves understanding each of these aspects of its design.
CLI 언어의 디자인에는 모든 언어에 공통으로 적용되는 세가지 중요한 관점이있다.
첫째는 CTS (Common Type System)이라 불리는 .Net Framework가 지원하는 공통 타입 체계로 언어 레벨의 문법을 맵핑하는 것이고 둘째는 프로그래머에게 하부 구조인 CLI infrastructure로의 접근 디테일을 얼마만큼 드러낼 것인가이고 셋째는 CLI에 의해 직접적으로 지원되는 것을 넘어서는 추가적인 능력을 선택하는 것이다.
일반적으로 첫번째 관점은 모든 CLI 언어에 공통적인 요소이다. 둘째와 셋째가 CLI 언어를 구분 짓게 되는 요소들인데 어떤 문제에 직면했느냐에 따라서, 또 어떤 언어를 선택하느냐에 따라서 당신은 여러개의 CLI 언어를 사용할지도 모른다. C++/CLI를 배운다는 것은 이 모든 세가지 디자인 관점을 이해하는 것을 필요로 한다. 즉, 이해력 만렙 찍어야 한다.
참고로 CTS는 .NET Framework가 가지고 있는 한가지의 요소로써 서로 다른 언어들이 표현하는 같은 형태의 타입들을 모아모아 일관된 형태로 표현하는 일종의 명세(Specification)같은 거라고 생각하면 대략 괜찮다. 사실, 모든 발전된 형태의 언어나 프레임워크는 새로운 것이 아니라 기존의 것을 잘 포장하고 싸놓은 것이다. C++이 추상화와 상속을 통해 객체 지향을 하는 것처럼 .NET Framework도 언어들 간에 추상화와 단일화된 규약을 통해 통합을 시도한 것이라고 보면 된다.
Mapping C++/CLI to the CTS?
It is important when programming C++/CLI to learn the underlying CTS, which includes these three general class types:
- The polymorphic reference type, which is what you use for all class inheritance.
- The non-polymorphic value type, which is used for implementing concrete types requiring runtime efficiency, such as the numeric types.
- The abstract interface type, which is used for defining a set of operations common to a set of either reference or value types that implement the interface.
CTS는 다음과 같은 세가지 일반적 클래스 타입을 가진다.
- 다형적 레퍼런스 타입: 클래스 상속을 위해 사용되는 것
- 다형적이지 않은 값 타입: 이러한 녀석은 runtime 효율성을 위해서 필요한 concrete type들인데 예를 들자면 숫자 타입들 (int, float)
- 추상적 인터페이스 타입: 이것은 인터페이스를 구현하는 레퍼런스나 값 타입의 공통된 operation들을 정의하기 위해 사용되는 것
말은 참 어렵게 써놓긴 했는데 단순하게 생각하면 C++ 클래스의 상속과 추상 클래스를 떠올리면 거의 맞아 떨어진다.
와우, 아래의 글을 좀 읽어봤는데 생각보다 내용이 깊다. 물론 CLI와 .NET Framework의 관계를 이해하는데는 엄청난 도움이 될 것이 분명하지만 이 글을 읽게된 이유는 코드 프로젝트 때문이기 때문에 일단 여기서 멈추고 나머지 부분은 차후에 번역해야 겠다.
This design aspect, the mapping of the CTS to a set of built-in language types, is common across all CLI languages although, of course, the syntax varies in each CLI language. So, for example, in C#, you would write
abstract class Shape { ... } // C#
to define an abstract Shape base class from which specific geometric objects are to be derived, while in C++/CLI you write
ref class Shape abstract { ... }; // C++/CLI
to indicate the exact same underlying CLI reference type. The two declarations are represented exactly the same way in the underlying IL. Similarly, in C#, you write
struct Point2D { ... } // C#
to define a concrete Point2D class, while in C++/CLI you write:
value class Point2D { ... }; // C++/CLI
The family of class types supported with C++/CLI represents an integration of the CTS with the native facilities, and that determines your choice of syntax. For example:
class native {};
value class V {};
ref class R {};
interface class I {};
The CTS also supports an enumeration class type that behaves somewhat differently from the native enumeration, and support is provided for both of those as well:
enum native { fail, pass };
enum class CLIEnum : char { fail, pass};
Similarly, the CTS supports its own array type that again behaves differently from the native array. And again Microsoft provides support for both:
int native[] = { 1,1,2,3,5,8 };
array<int>^ managed = { 1,1,2,3,5,8 };
No CLI language is closer to or more nearly a mapping to the underlying CTS than another. Rather, each CLI language represents a view into the underlying CTS object model.
CLI Level of Detail
The second design aspect that must be considered when designing a CLI language is the level of detail of the underlying CLI implementation model to incorporate into the language. What kind of problems will the language be tasked to solve? Does the language have the tools necessary to do this? Also, what sort of programmers is the language likely to attract?
Take, for example, the issue of value types occurring on the managed heap. Value types can find themselves on the managed heap in a number of circumstances:
- Through implicit boxing, when an instance of a value type is assigned to an Object or when a virtual method is invoked through a value type that is not overridden.
- When that value type is serving as a member of a reference class type.
- When that value type is being stored as the element type of a CLI array.
Whether the programmer should be allowed to manipulate the address of a value type of this sort is a CLI language design consideration that must be addressed.
What Are the Issues?
Any object located on the managed heap is subject to relocation during the compaction phase of a sweep of the garbage collector. Any pointers to that object must be tracked and updated by the runtime; the programmer cannot manually track it herself. Therefore, if you were allowed to take the address of a value type that might be on the managed heap, there would need to be a tracking form of pointer in addition to the existing native pointer.
What are the trade-offs to consider? On the one hand, there's simplicity and safety. Directly introducing support in the language for either one or a family of tracking pointers makes it a more complicated language. By not supporting this, the available pool of programmers is expanded because less sophistication is required. In addition, allowing the programmer access to these ephemeral value types increases the possibility of programmer error—she may purposely or inadvertently do dangerous things to the memory. By not supporting tracking pointers, a potentially safer runtime environment is created.
On the other hand, efficiency and flexibility must be considered. Each time you assign the same Object with a value type, a new boxing of the value occurs. Allowing access to the boxed value type allows in-memory update, which may provide significant performance improvements. Without a form of tracking pointer, you cannot iterate over a CLI array using pointer arithmetic. This means that the CLI array cannot participate in the Standard Template Library (STL) iterator pattern and work with the generic algorithms. Allowing access to the boxed value type allows significant design flexibility.
Microsoft chose to provide a collection of addressing modes that handle value types on the managed heap in C++/CLI:
int ival = 1024;
int^ boxedi = ival;
array<int>^ ia = gcnew array<int>{1,1,2,3,5,8};
interior_ptr<int> begin = &ia[0];
value struct smallInt { int m_ival; ... } si;
pin_ptr<int> ppi = &si.m_ival;
The typical C++/CLI developer is a sophisticated system programmer tasked with providing infrastructure and organizationally critical applications that serve as the foundation over which a business builds its future. She must address both scalability and performance concerns and must therefore have a system-level view into the underlying CLI. The level of detail of a CLI language reflects the face of its programmer.
Complexity is not in itself a negative quality. Human beings are more complicated than single-cell bacteria, and that is certainly not a bad thing. However, when the expression of a simple concept is made complicated, that is usually considered to be a bad thing. In C++/CLI, the CLI team has tried to provide an elegant way to express complex subject matter.
Additional Functionality
A third design aspect is a language-specific layer of functionality above and beyond what is directly supported by the CLI. This may require a mapping between the language-level support and the underlying implementation model of the CLI. In some cases, this just isn't possible because the language cannot intercede with the behavior of the CLI. One example of this is the virtual function resolution in the constructor and destructor of a base class. To reflect ISO-C++ semantics in this case would require a resetting of the virtual table within each base class constructor and destructor. This is not possible because virtual table handling is managed by the runtime and not by the individual language.
So this design aspect is a compromise between what would be preferable to do, and what is feasible. The three primary areas of additional functionality that are provided by C++/CLI are the following:
- A form of Resource Acquisition is Initialization (RAII) for reference types, in particular, to provide an automated facility for what is referred to as deterministic finalization of garbage- collected types that hold scarce resources.
- A form of deep-copy semantics associated with the C++ copy constructor and copy assignment operator; however, these semantics could not be extended to value types.
- Direct support of C++ templates for CTS types in addition to the CLI generic mechanism. In addition, a verifiable version of the STL for CLI types is provided.
Let's look at a brief example: the issue of deterministic finalization. Before the memory associated with an object is reclaimed by the garbage collector, an associated Finalize method, if present, is invoked. You can think of this method as a kind of super-destructor since it is not tied to the program lifetime of the object. This is called finalization. The timing of just when or even whether a Finalize method is invoked is undefined. This is what is meant by nondeterministic finalization of the garbage collector.
Nondeterministic finalization works well with dynamic memory management. When available memory gets sufficiently scarce, the garbage collector kicks in and solves the problem. Nondeterministic finalization does not work well, however, when an object maintains a critical resource such as a database connection, a lock of some sort, or perhaps native heap memory. In this case, it would be great to release the resource as soon as it is no longer needed. The solution that is currently supported by the CLI is for a class to free the resources in its implementation of the Dispose method of the IDisposable interface. The problem here is that Dispose requires an explicit invocation, and therefore is not likely to be invoked.
A fundamental design pattern in C++ is the aforementioned Resource Acquisition is Initialization, which means that a class acquires resources within its constructor. Conversely, a class frees its resources within its destructor. This is managed automatically within the lifetime of the class object.
Here's what reference types should do in terms of the freeing of scarce resources:
- Use the destructor to encapsulate the necessary code for the freeing of any resources associated with the class.
- Have the destructor invoked automatically, tied with the lifetime of the class object.
The CLI has no notion of the class destructor for a reference type. So the destructor has to be mapped to something else in the underlying implementation. Internally, then, the compiler performs the following transformations:
- The class has its base class list extended to inherit from the IDisposable interface.
- The destructor is transformed into the Dispose method of IDisposable.
That represents half of the goal. A way to automate the invocation of the destructor is still needed. A special stack-based notation for a reference type is supported; that is, one in which its lifetime is associated within the scope of its declaration. Internally, the compiler transforms the notation to allocate the reference object on the managed heap. With the termination of the scope, the compiler inserts an invocation of the Dispose method—the user-defined destructor. Reclamation of the actual memory associated with the object remains under the control of the garbage collector. Figure 1 shows an example.

Figure 1 Invoking the Destructor
ref class Wrapper {
Native *pn;
public:
// resource acquisition is initialization
Wrapper( int val ) { pn = new Native( val ); }
// this will do our disposition of the native memory
~Wrapper(){ delete pn; }
void mfunc();
protected:
// an explicit Finalize() method—as a failsafe
!Wrapper() { delete pn; }
};
void f1()
{
// normal treatment of a reference type
Wrapper^ w1 = gcnew Wrapper( 1024 );
// mapping a reference type to a lifetime
Wrapper w2( 2048 ); // no ^ token !
// just illustrating a semantic difference
w1->mfunc();
w2.mfunc();
// w2 is disposed of here
}
//
// ... later, w1 is finalized at some point, maybe
C++/CLI is not just an extension of C++ into the managed world. Rather, it represents a fully integrated programming paradigm similar in extent to the earlier integration of the multiple inheritance and generic programming paradigms into the language. I think the team has done an outstanding job.
So, What Did You Say About C++/CLI?
C++/CLI represents an integration of native and managed programming. In this iteration, that has been done through a kind of separate but equal community of source-level and binary elements, including Mixed mode (source-level mix of native and CTS types, plus a binary mix of native and CIL object files), Pure mode (source-level mix of native and CTS types, all compiled to CIL object files), Native classes (can hold CTS types through a special wrapper class only), and CTS classes (can hold native types only as pointers). Of course, the C++/CLI programmer can also choose to program in the CLI types alone, and in this way provide verifiable code that can be hosted, for example, as a stored procedure in SQL Server™ 2005.
So, returning to the question, what is C++/CLI? It is a first-class entry visa into the .NET programming model. With C++/CLI, there is a C++ migration path not just for the C++ source base but for C++ expertise as well. I find great satisfaction in that.