
출처: http://duartes.org/gustavo/blog/post/getting-physical-with-memory/
저자: Gustavo Duarte
이 글도 상당히 도움이 되는 글인듯 하여 번역하여 옮겨둔다.
원래 복잡한 시스템을 이해하려면 가장 기초가 되는 원초적인 것을 들여다 볼 필요가 있다. 그런 점에서 우리는 프로세서와 버스 간의 인터페이스에 대해서 알아보자... 저자는 EE 전공자가 아니므로 EE 친구들이 걱정하는 그런 부분은 가뿐히 무시하겠다고... CS! CS! /yay
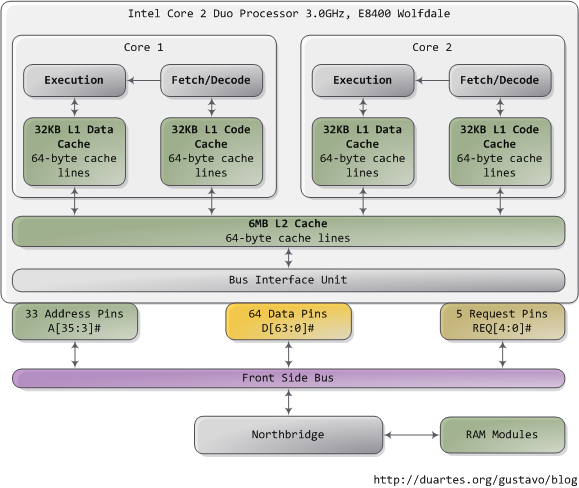
위의 그림은 Core 2 디자인이다. 코어 2의 경우 775개의 핀을 가지고 있다. 그중 절반은 파워만 제공하고 데이터를 운송하지 않는다. 그럼 대략 387.5 개 인가? 작동하는 핀들을 그룹으로 묶어주면 사실 코어2의 디자인은 상당히 단순하다. 위의 그림을 보면 중요한 핀들을 보여주고 있는데 Address pin, Data pin, Request pin 들이다. 이 동작들은 FSB (Front Side Bus)라 불리는 곳에서 이른바 Transaction이라는 이름으로 시행되는데 FSB Transaction은 5개의 페이즈를 가지고 있단다. Arbitration, Request, Snoop, Response, Data 요렇게 다섯가지. Agent라 함은 프로세서에 Northbridge까지 포함한다. 한국말로 요원들이라고 해야 겠군... 이 요원들이 다섯가지 페이즈를 호출하여 사용하는데 각각 다른 형태의 임무를 수행한다는 군...
우리가 관심있는 분야는 오직 Request Phase다. Request Agent (주로 한개의 프로세서) 에 의해 2개의 packet이 출력으로 나오는 페이즈가 바로 Request Phase.
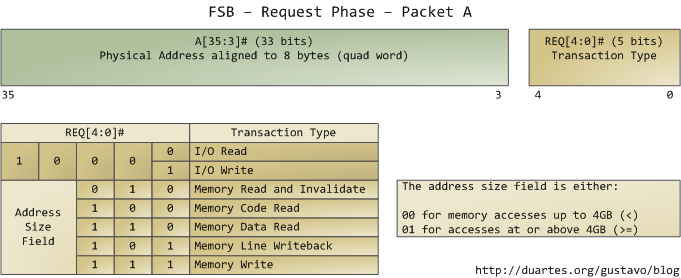
위 그림처럼 35-3 (33 비트)의 길이를 가지는 필드를 먼저 보게 되는데 이것은 물리 주소를 알려주는 필드이다. 그리고 바로 뒤에 REQ 핀이 오는데 이 녀석의 각 비트 값에 따라 어떠한 형태의 접근 및 처리를 원하는지 알려준다. 이 첫번째 패킷이 나간 후에 바로 두 번째 패킷이 나가는데 아래 그림과 같다.
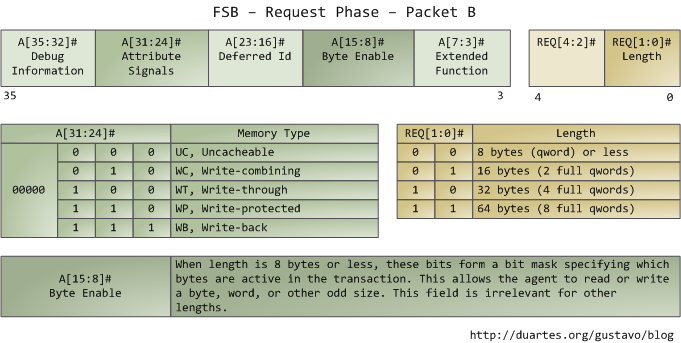
여기서 재미 있는 부분은 바로 Attribute Signals 필드인데 (31:24) 여기를 보면 메모리 캐싱 동작의 5가지 종류에 대해서 정의하고 있다. FSB에 이 정보를 제공함으로써 Request Agent는 다른 프로세서들에게 이 Transaction이 그들의 캐시에 영향을 주는지 알려주며 메모리 컨트롤러인 Northbridge에게 어떻게 동작해야 하는지도 알려준다. 프로세서는 커널에 의해 작성되는 page table을 참조하여 주어진 메모리 영역의 타입을 결정한다.
일반적으로 커널은 모든 RAM 영역을 write-back으로 간주하는데 그것이 최상의 퍼포먼스를 내기 때문이다. Write-back 모드에서는 메모리 액세스의 단위가 cache line 이 되고 이것은 64 바이트이다 (코어2에서). 만약 하나의 프로그램에서 1 바이트를 메모리에서 읽으면 프로세서는 그 1바이트를 담고 있는 전체 cache line 을 L2 와 L1 캐시에 로드한다. 또한 프로그램이 메모리에 쓰는 경우, 프로세서는 캐시에 있는 라인만 수정하고 main memory는 업데이트 하지 않는다. 나중에, 처리해야 하는 시점이 오면 그제서야 cache line 전체를 한방에 메인 메모리로 써버린다. 고로 대부분의 request는 Length field가 11 (64 bytes) 값을 가지고있다. 다음 그림을 보면 캐시에 없는 데이터를 어떻게 읽어들이는지 보여준다.
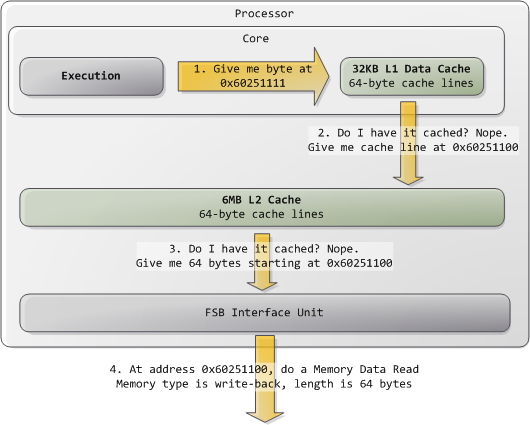
위 그림을 보아하니 대충 이해가 간다. 프로그램이 특정 주소를 달라고 요청하게 되면 우선 L1 캐시에 있는지 확인해보고 없으면 L2로 가고 거기도 없으면 FSB로 요청해 그 주소로 직접적인 액세싱을 하게 된다는 거. 길이는 64바이트로 고정되어 있군.
추가적으로 인텔 컴퓨터의 일부 메모리 영역은 장치로 연결된 경우가 있다. 즉, 메모리 영역이 실질적인 RAM이 아니라 하드 드라이브의 일부이거나 네트워크 상의 공간일 수 있다는 것인데 이런경우에는 커널이 이런 주소 영역을 uncacheable 로 도장을 쾅 찍어둔다. 당연히 이런 주소 공간을 캐시에 담아둔다는 것은 말이 안된다. 이런 경우에는 길이가 64바이트가 아닐수 있으므로 Length field가 64 바이트가 아닐수 있다는 점..
글의 결론은
1. 퍼포먼스가 중요한 프로그램의 경우에는 같은 캐시 라인 안에 필요한 데이터를 팩킹해서 처리하도록 노력하는 것이 성능향상에 도움이 된다. 캐시에서 바로 가져오는 경우 성능의 향상이 어마어마 하다.
2. 하나의 cache line 안에 포함되는 메모리 엑세싱은 Atomic 이 보장된다. 원소성이라고 하는데 이것이 좋은 이유는 중간에 다른 스레드가 개입하여 중단하는 일이 없기 때문이다. 즉, 멀티 스레드에도 안전성을 제공한다는 거.
3. FSB는 모든 에이전트에 의해 공유된다. 모든 에이전트는 모든 transaction을 듣고 있어야 하는데 이런 것이 FSB에 교통혼잡을 유발하고 성능을 떨어뜨리는 이유가 되었다. 바로 Core i7에서는 이러한 문제를 해결하기 위해 프로세서가 바로 메모리로 접근할수 있도록 변경했다. 그것이 성능 향상에 큰 도움.
'프로그래밍 > C++' 카테고리의 다른 글
| Anatomy of a Program in Memory (0) | 2016.02.06 |
|---|---|
| typename에 대해 좋은글 발견! (0) | 2014.08.28 |
| __try / __finally 예제 코드 (0) | 2012.12.18 |
| iexpress를 이용한 어플리케이션 재배포 패키지 만들기 (0) | 2012.12.15 |
| Determining which DLLs to Redistribute (어떤 DLL을 재배포할껀가?) (0) | 2012.12.15 |